Separating the Best Education Apps From, Well, the Rest
CORRECTED
Educators are being inundated with apps that promise to help them make their lessons richer, and more fun. But distinguishing a top-flight app from a shoddy one is no easy thing.
With that challenge in mind, a group of college faculty has put forward research standards for judging the quality of those mobile software tools. The title they gave their efforts at the recent International Society for Technology in Education conference, held in Atlanta, offered a colorful summary of their view of the existing app ecosystem:
“There’s a lot of crAPP out There! App Evaluation”
Kristi L. Shaw, of Marian University, in Wisconsin, and Malia M. Hoffmann, of Concordia University, in California, both of whom have studied tech-based learning in their academic work, set up a booth at the massive ed-tech gathering to explain their efforts to help teachers, and even students, evaluate the quality of apps based on research. Along with Tonya Hameister, also of Marian University, they’ve established “research-based rubrics” for evaluating whether apps provide sound educational content and instructional strategies.
The college faculty members’ rubrics focus on four categories of apps: those being used in math; special education; other, non-math related content; and those to help students evaluate apps. The rubrics are available on a website the researchers launched earlier this year.
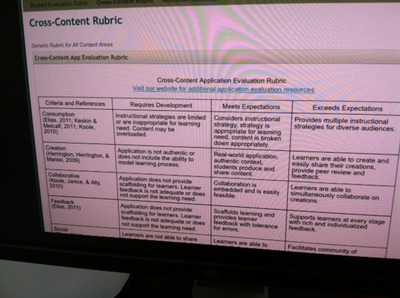 “It seems like teachers are grabbing any free apps they can find,” Shaw told Education Week, in between greeting visitors to the ISTE booth. “People are not looking at things critically. [This] is a way for teachers to think about what tools they’re using.”
“It seems like teachers are grabbing any free apps they can find,” Shaw told Education Week, in between greeting visitors to the ISTE booth. “People are not looking at things critically. [This] is a way for teachers to think about what tools they’re using.”
The project undertaken by Shaw and company underscored a common theme at the ISTE summit, where a number of sessions were devoted to helping K-12 officials sort through through the often daunting ed-tech landscape and choose tools, platforms, and programs that have strong track records, or at least the greatest potential to help students.
Shaw said she knows of a few similar efforts to help teachers evaluate apps, though she believes the Marian-Concordia venture is the one most focused on what academic research actually says about the mobile software.
Each of the rubrics sets specific criteria for evaluating the apps, based on the intent of the application: consumption, creation, collaboration, feedback, social, and intuitive interface/maximixing device capability. For instance, if the goal of the app is to help users consume information, a K-12 official would follow that row for guidance. If the goal is to create content, or create a collaborative workspace, such as through Creative Book Builder, a teacher would follow the collaborative row, Shaw said. (See a photo of the researchers’ rubrics, taken at their ISTE booth, right.) The website also includes specific references to research against which apps can be evaluated.
Those using the rubrics are invited to judge the apps by three standards: “requires development”; “meets expectations”; or “exceeds expectations,” with descriptions offered for each of those standards.
The research team’s primary audience is K-12 teachers, Shaw explained. She said they haven’t heard any feedback from app developers yet, though that could be coming. Going forward, the researchers are likely to survey technology coaches to see how K-12 schools are using the rubrics, and how useful they are for teachers and students.
At a conference that drew about 16,000 attendees and more than 500 vendors, Shaw and Hoffman were looking for ways to stand out. Their title, which drew compliments and chuckles from passers-by, seemed to do the trick.
“I texted it to her and said, ‘Is this too risky?’ ” Shaw said, turning to her companion.
“And I said, ‘No, I love it,” Hoffmann responded.
[CORRECTION: The original post mispelled the name of Malia Hoffman of Concordia University.]